Kernpunkte:
- Plattform Privatheit
- DatenTRAFO – Neue Datenschutz-Governance
- Transparenz für das Internet der Dinge
- TRUMAN – Vertrauenswürdige KI-Anwendungen
- AnoMed – Anonymisierung für medizinische Anwendungen
8 Modellprojekte und Studien
Das Unabhängige Landeszentrum für Datenschutz hat als Behörde der Landesbeauftragten für Datenschutz seine Aktivitäten in drittmittelfinanzierten Projekten und Studien fortgesetzt. Damit kooperiert das ULD weiterhin aktiv mit der Wissenschaft und kann zusammen mit Wissenschaftspartnern proaktiv an der Erforschung datenschutzspezifischer Fragen und der Gestaltung einschlägiger Technologien mitwirken. Gefördert wurden die im Berichtsjahr laufenden Projekte seitens des Bundesministeriums für Forschung, Technologie und Raumfahrt (BMFTR, vormals Bundesministerium für Bildung und Forschung) und der Europäischen Kommission. Beteiligungen an Projekten erfolgten weiterhin primär dort, wo datenschutzfördernde Technik (englisch: „Privacy-Enhancing Technologies“, kurz PETs) erforscht, entwickelt oder in die Praxis transferiert wird oder wo besondere Risiken für die Rechte und Freiheiten natürlicher Personen bestehen.
Im Jahr 2025 beteiligte sich das ULD an Projekten zu aktuellen Themen in den Bereichen Privatheit und selbstbestimmtes Leben (Tz. 8.1), Überführung von Lösungen des Datenschutzes durch Technikgestaltung in die Praxis (Tz. 8.2), Transparenzprobleme des Internets der Dinge (Tz. 8.3) sowie im Bereich der künstlichen Intelligenz (Tz. 8.4). Zudem setzte das ULD sein Engagement zu Anonymität für Medizinforschung mit Gesundheitsdaten fort (Tz. 8.5).
8.1 Plattform Privatheit: Forschung für ein selbstbestimmtes Leben in der digitalen Welt
Viele Jahre wirkt das ULD nun schon in der Plattform Privatheit (vormals: Forum Privatheit) mit. Dabei handelt es sich um ein vom BMFTR gefördertes, bundesweites Vernetzungsprojekt, dessen oberstes Ziel es ist, mit interdisziplinärer Forschung die informationelle Selbstbestimmung aller Bürgerinnen und Bürger zu stärken. Zudem unterstützt die Plattform Privatheit eine technologische Entwicklung, die dem Gemeinwohl dient. Die Plattform Privatheit vernetzt und begleitet eine Vielzahl interdisziplinärer Projekte, in denen Wissenschaftlerinnen und Wissenschaftler aus unterschiedlichen Disziplinen rechtliche, technische und organisatorische Lösungen entwickeln, die es den Menschen ermöglichen, im digitalen Alltag ihre Grundrechte und europäischen Werte zu wahren.
So hilft die Plattform Privatheit mittlerweile mehr als 30 Projekten bei der Vernetzung, darunter auch den vom BMFTR geförderten Projekten mit ULD-Beteiligung. Veröffentlichungen zu datenschutzrelevanten Schnittstellenthemen sind ebenso wie die Tagungsbände der Jahreskonferenz in Berlin, an der Interessierte online oder vor Ort teilnehmen können, kostenlos.
Weitere Informationen über die Plattform Privatheit lassen sich der Website entnehmen:
https://www.plattform-privatheit.de[Extern]
Kurzlink: https://uldsh.de/tb44-8-1a
8.2 Projekt DatenTRAFO – Neue Datenschutz-Governance – Technik, Regulierung und Transformation
Das Projekt „Neue Datenschutz-Governance – Technik, Regulierung und Transformation (DatenTRAFO)“ entwickelt Vorschläge, wie Datenschutz in der Praxis umgesetzt werden kann, wird vom BMFTR gefördert und läuft vom 1. September 2023 bis 31. August 2026. Bei DatenTRAFO war das Jahr 2024 von den neuen EU-Regelungen geprägt, insbesondere der Verordnung 2024/1689 zu künstlicher Intelligenz (KI-Verordnung), die die Regelungen der DSGVO im Bereich der künstlichen Intelligenz ergänzt und erweitert.
KI-Verordnung
Die EU hat im Jahr 2024 die KI-Verordnung beschlossen, die nun in den kommenden Jahren von Behörden und Unternehmen angewendet werden muss. In bestimmten Bereichen verbietet sie den Einsatz von KI-Systemen, z. B. zur Erkennung von Gesichtern auf Videos von Überwachungskameras in Echtzeit. Allerdings gibt es dabei zahlreiche Ausnahmen, wie etwa für den besonders grundrechtssensiblen Bereich der polizeilichen Überwachung.
DatenTRAFO hat insbesondere die sogenannte Grundrechte-Folgenabschätzung und das Risikomanagementsystem der KI-Verordnung untersucht. Anders als die DSGVO, die sich nur an Verantwortliche richtet, also an die Stelle, die über eine Datenverarbeitung entscheidet, verpflichtet die KI-Verordnung auch diejenigen, die KI-Systeme entwickeln und in der KI-Verordnung als Anbieter bezeichnet werden. Das gilt auch für die Abwägung von Grundrechtsrisiken für Nutzende. Von einem solchen Modell könnten auch die DSGVO und die darin vorgesehene Datenschutz-Folgenabschätzung profitieren. Eine Risikoabwägung würde für Verantwortliche leichter, wenn sie auf eine Abschätzung von Risiken seitens des Herstellers zurückgreifen könnten. Zudem bestehen zwischen der Grundrechte-Folgenabschätzung und der Datenschutz-Folgenabschätzung zahlreiche Überschneidungen, sodass durch eine Angleichung der Regelungen eine Entlastung für Unternehmen bei gleichzeitiger Wahrung der Rechte der betroffenen Personen erreicht werden könnte.
In der aktuellen Diskussion zur Reform von DSGVO und KI-Verordnung werden diese Punkte noch nicht ausreichend berücksichtigt. Die Bundesregierung und die Länder haben jedoch vorgeschlagen, in der DSGVO zukünftig Pflichten auch für Hersteller von bestimmten Diensten und Produkten einzuführen.
Was ist zu tun?
Die DSGVO sollte um Pflichten für Hersteller von Diensten und Produkten erweitert werden. Wird dies umgesetzt, kann auch die Grundrechte-Folgenabschätzung durch die bereits bewährte Datenschutz-Folgenabschätzung abgelöst werden, da sie ohnehin für viele KI-Systeme vorzunehmen ist. Dies entlastet Unternehmen und sichert die Grundrechte betroffener Personen.
8.3 Projekt Unboxing.IoT.Privacy – Transparenz für Datenschutzeigenschaften von IoT-Geräten
Vernetzte Geräte werden zunehmend allgegenwärtig und bringen Vorteile und Nachteile des Internets der Dinge (englisch: „Internet of Things“, IoT) direkt zu den Menschen (43. TB, Tz. 8.3). Seit 2023 befasst sich das vom Bundesministerium für Forschung, Technologie und Raumfahrt (BMFTR) geförderte Projekt „Tool-gestützte, moderierte und bürgerzentrierte Community-Plattform zur Privacy-Einstufung von IoT-Produkten – Unboxing.IoT.Privacy“ mit Aspekten der Transparenz und des Datenschutzes bei solchen Geräten.
Eines der Projektziele ist es, Transparenz über die Datenverarbeitung solcher Geräte zu unterstützen. Vielfach fehlen schlicht relevante Informationsquellen für interessierte Verbraucherinnen und Verbraucher, potenziell Betroffene oder datenschutzrechtlich Verantwortliche. Geeignete Informationen sollten am besten schon für die Kaufentscheidung oder den Vertragsschluss mit dem Dienstleister vorliegen, damit eine angemessene Bewertung und Risikoeinschätzung erfolgen können. In neueren europäischen Rechtsakten werden diese Transparenz- und Datenschutz-Problemstellungen teilweise angesprochen, wenn auch nicht explizit mit Datenschutz als Zielsetzung. So nimmt die Cyberresilienz-Verordnung (englisch: „Cyber Resilience Act“, CRA) Hersteller, Importeure und Verkäufer u. a. von IoT-Geräten in die Pflicht, nicht nur bestimmte Sicherheitseigenschaften zu gewährleisten, sondern auch Informationen bereitzustellen, die direkt oder mittelbar datenschutzrechtlichen Transparenzzielen dienen (dazu 43. TB, Tz. 8.3).
Datenverordnung
Die Datenverordnung (englisch: „Data Act“) ist Teil der Datenstrategie der EU-Kommission und enthält Regeln für Zugang, Nutzung und Weitergabe von Daten aus vernetzten Geräten. Nutzerinnen und Nutzer können entscheiden, ihre Daten selbst zu erhalten oder diese an Dritte weiterzugeben. Haben nutzergenerierte Daten einen Personenbezug, so richtet sich deren Verarbeitung nach der DSGVO.
Mit der Datenverordnung (englisch: „Data Act“, DA) hat der europäische Gesetzgeber weitere Regelungen geschaffen, die gleichsam Hersteller und weitere Akteure zur Informationsbereitstellung verpflichten. Ein Hauptziel des DA ist es, die bei der Gerätenutzung anfallenden Daten bereitzustellen und deren Nutzung zu ermöglichen. Dafür sind Geräte u. a. künftig so zu gestalten, dass Nutzende die anfallenden Daten einfach auslesen können. Weiter haben Nutzende ein Recht auf Zugänglichmachung, wenn die Daten bei einem Anbieter eines verbundenen Dienstes (Dateninhaber) vorliegen. Hersteller bzw. Diensteanbieter haben künftig u. a. über Art, Format, Umfang der erhobenen Produktdaten und erzeugten Dienstdaten, Identität des Dateninhabers sowie Modalitäten über die Zugriffsmöglichkeiten zu informieren.
Die Datenverordnung bezieht sich dabei auf „Daten“, unabhängig davon, ob ein Personenbezug besteht. Für personenbezogene Daten geht im Falle eines Widerspruchs zwischen DSGVO und Datenverordnung erstere vor. In einfach gelagerten Fällen besteht weitgehender Gleichlauf zwischen Rechten und Pflichten aus DSGVO und Datenverordnung. Dies ist etwa der Fall, wenn Nutzende eines IoT-Geräts zugleich die jeweils einzigen von der Verarbeitung betroffenen Personen sind, wie etwa bei vernetzten Sportuhren.
Sobald Drittbetroffene involviert sind, wie z. B. weitere Hausbewohner, die von Sensoren erfasst werden, steigt die Komplexität. Eine korrekte Fallbeurteilung setzt dann zwingend eine saubere Zuordnung der Rollen nach DA und DSGVO im konkret vorgesehenen Einsatzszenario voraus (siehe Abb. 3 auf der nächsten Seite).
Erst aus der genauen Rollenzuordnung ergeben sich die Rechte und Pflichten zwischen den Akteuren. Herausforderungen im Spannungsfeld zwischen DSGVO und DA können sich etwa für Dateninhaber ergeben.
Insbesondere betrifft dies die Bereitstellungspflicht für personenbezogene Daten, die Diensteanbieter während der Erbringung eines verbundenen Dienstes abgerufen oder generiert haben. Datenschutzrechtlich bedarf es einer gültigen Rechtsgrundlage. Gleichzeitig besteht gemäß dem DA die Bereitstellungspflicht zumindest für nicht personenbezogene Daten. Dateninhaber gelangen so in die undankbare Lage, über den Personenbezug von Daten befinden zu müssen, obwohl sie die Umstände der Erhebung kaum kannten oder beeinflussen konnten. Eine denkbare rechtliche Lösung wäre, dass verbundene Dienste strikt im Rahmen einer Auftragsverarbeitung für die Nutzenden der Geräte tätig werden, sodass Letztere allein datenschutzrechtlich Verantwortliche wären. Diese Lösung widerspräche aber dem politischen Ziel, die Daten aus vernetzten Geräten weiteren Zwecken zuzuführen. Hier werden denkbare Lösungsansätze noch zu bewerten sein.
Interessant sind hier insbesondere vertragliche Regelungen, da Dateninhaber ohnehin für die Datennutzung einen Vertrag mit den Nutzenden benötigen. Dann könnte im selben Streich eine gemeinsame Verantwortlichkeit geregelt werden.
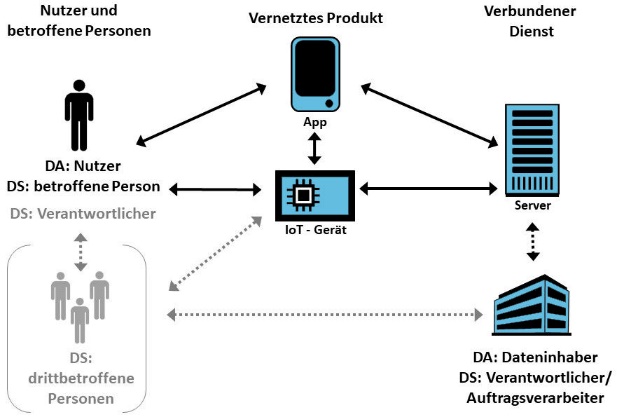
Abb. 3: Akteure und Rollen beim Einsatz von IoT-Geräten
Einen Link mit weiteren Informationen finden Sie unter:
https://www.datenschutzzentrum.de/projekte/unboxingiot/
Kurzlink: https://uldsh.de/tb44-8-3a[Extern]
Abb. 3: Akteure und Rollen beim Einsatz von IoT-Geräten
8.4 Projekt TRUMAN – Der Mensch im Mittelpunkt: vertrauenswürdige KI-Anwendungen
In den letzten Jahren sind die Entwicklungen im Bereich der künstlichen Intelligenz (KI) in vielen Branchen weit vorangeschritten und haben zu wichtigen Erkenntnissen und Durchbrüchen in Bereichen wie Gesundheitswesen, Verkehr, Finanzen und Fertigung geführt. KI wurde zu einem wichtigen Wachstumsmotor für den gesamten Bereich der Informationstechnologie. Zugleich wirft der Einsatz von KI viele Fragen auf, die einer Lösung bedürfen, insbesondere wenn durch KI Rechte von Individuen berührt werden. Das von der Europäischen Kommission finanzierte Projekt „TRUstworthy huMAN-centric artificial intelligence – TRUMAN“ zielt darauf ab, vertrauenswürdige und datenschutzkonforme KI-Systeme zu entwickeln, die den Anforderungen der DSGVO und der KI-Verordnung entsprechen. Im Mittelpunkt stehen technische und organisatorische Maßnahmen, die Transparenz und menschliche Kontrolle sicherstellen. Hinsichtlich der technischen Umsetzung soll die Vertrauenswürdigkeit von KI erhöht werden, indem Robustheit, Erklärbarkeit sowie menschliche Kontrollierbarkeit in allen Phasen des KILebenszyklus (Datengewinnung, Modelltraining, Ausführung) integriert werden.
Das Projekt sucht für die sich aus KI stellenden datenschutzrechtlichen Herausforderungen Lösungen, die rechtliche, ethische und technische Anforderungen in Einklang bringen. Für den Datenschutz sollen die Gewährleistungsziele u. a. durch dezentrale Lerntechniken und mehr Verständlichkeit und Transparenz gestärkt werden. Als mögliche Maßnahmen für Datenschutz durch Technikgestaltung werden u. a. föderiertes Lernen, synthetische Datenerzeugung und Differential-Privacy-Mechanismen betrachtet.
Ein Alleinstellungsmerkmal von TRUMAN ist die Integration des Projektziels „Explainability and Usability“, das sich auf die verständliche Vermittlung der internen Vorgänge der KI sowie von Datenschutz- und Sicherheitsmaßnahmen konzentriert. Ziel ist es, Verantwortlichen sowie Nutzenden leicht nachvollziehbare Informationen über die Art der Datennutzung, die Funktionsweise der Sicherheits- und Datenschutzmechanismen und die möglichen Datenschutzrisiken anzubieten. Das Systemverhalten soll aus Nutzendenperspektive erklärbar sein bzw. verständlich werden. Diese „usable explanations“ unterstützen Verantwortliche bei der Einhaltung des Transparenzgebots und bezwecken gleichzeitig eine gestärkte Vertrauenswürdigkeit von KI-Systemen, die diese Methoden unterstützen.
Die Beiträge des ULD zu datenschutzrechtlichen Aspekten erfolgen vor allem zu zwei zentralen Projektzielen. Das Projektziel „Human-in-the-Loop – Verteiltes dynamisches Lernen“ fokussiert sich auf KI und maschinelles Lernen. Es dient als Ausgangspunkt für das weitere Projekt und definiert Eigenschaften und Spezifikationen für KI-Techniken und die zu erforschenden Lösungen. Die drei Schlüsselbegriffe für dieses TRUMAN-Projektziel sind:
- „Human-in-the-Loop (HITL)“, da der Mensch eine wichtige Rolle bei der Verbesserung von KI-Systemen spielt und Aufsicht und Kontrolle durch Menschen und die faktische und technische Möglichkeit dazu in allen Phasen des KI-Lebenszyklus erforderlich sind.
- „Verteilt“, da Daten oft dezentral am Standort des Diensteanbieters, Verbrauchers oder eines vernetzten Geräts entstehen und ein zentrales Sammeln und Zusammenführen datenschutzrechtlich unerwünscht ist.
- „Dynamisch”, da Daten im Laufe der Zeit kontinuierlich anfallen und sich weiterentwickeln.
Im Rahmen des Projektziels „Vertrauenswürdigkeit durch Erklärbarkeit und Benutzerfreundlichkeit“ ergründet das Projektkonsortium, wie menschenzentrierte KI-Systeme ergänzt werden können, um die Erklärbarkeit des Systemverhaltens aus Sicht der Nutzenden zu verbessern. Dazu sollen Schutzziele und Metriken für vertrauenswürdige KI-Systeme ermittelt und nachvollziehbar definiert werden. Diese erfassen und abstrahieren die Anforderungen, die sich aus einschlägigen Gesetzen, der Rechtsprechung oder Leitlinien der für KI zuständigen Aufsichtsbehörden und Ethikgremien ergeben. Absehbar werden sich inhärente Zielkonflikte aufzeigen lassen – etwa zwischen Datenrichtigkeit und Vollständigkeit in Abwägung mit Datenminimierung. Derartige Konflikte werden aufgezeigt und mögliche Methoden zum Ausgleich bzw. zur Begrenzung der Risiken gesucht und bewertet. Schließlich werden auch Aspekte der Benutzerfreundlichkeit von KI aufgegriffen.
https://www.datenschutzzentrum.de/projekte/truman/[Extern]
Kurzlink: https://uldsh.de/tb44-8-4a
8.5 Projekt AnoMed – Kompetenzcluster Anonymisierung für medizinische Anwendungen
Der Kompetenzcluster „Anonymisierung für medizinische Anwendungen – AnoMed“ geht nun in die zweite Runde. Der Cluster wurde durch das Bundesministerium für Technologie und Raumfahrt sowie der Europäischen Union (NextGenerationEU) (43. TB, Tz. 8.4) gefördert und für eine Fortsetzung der Förderung um drei Jahre ausgewählt. Das Folgeprojekt setzt zum 1. Januar 2026 unter Koordination der Universität Lübeck die Arbeit mit neuen Forschungsfragen und -schwerpunkten rund um Anonymisierung und Pseudonymisierung sowie von Gesundheitsdaten fort. Im Konsortium trägt das ULD mit vorwiegend datenschutzrechtlicher Expertise bei. Das Projekt befasst sich mit vielversprechenden Technologien zum Schutz von Gesundheitsdaten, die insbesondere auf Differential Privacy oder maschinellem Lernen basieren.
Mit dem Europäischen Raum für Gesundheitsdaten (European Health Data Space, EHDS) wurde eine Blaupause für weitere Datenräume geschaffen und dessen Umsetzung kommt eine Vorreiterrolle für andere Datenräume zu. Die Europäische Datenstrategie sieht weitreichende Sekundärnutzungen von Daten für Gemeinwohl, Wirtschaft und Verwaltung vor. Die zur Forschung benötigten Daten sind meist personenbezogen und teils hochsensibel. Um sie für Datenräume nutzbar zu machen, ist es erforderlich, sie zu anonymisieren oder anderweitig ausreichende Schutzmaßnahmen zu treffen. Wo eine Anonymisierung nicht möglich ist, wird im Gesundheitsdatenraum eine pseudonyme Bereitstellung von Daten vorgesehen.
Datenräume bringen eine Vielzahl von Datenquellen für eine integrierte Analyse zusammen. Die Integration kann horizontal (gleiche Datenkategorien von vielen Personen) oder vertikal (Daten zu einer Person werden aus mehreren Quellen zusammengeführt) erfolgen:
horizontale
|
Die gleichen Daten von vielen Personen werden zusammengeführt. |
z. B. europäisches Lagebild, gespeist aus nationalen Daten |
vertikale Integration
|
Verschiedene Daten (Aspekte) der gleichen Person werden zusammengeführt. |
z. B. Zusammenhang von Gesundheit, Ernährung, Fitness |
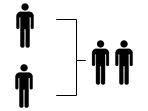
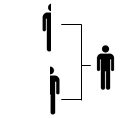
Verschiedene Integrationsarten erfordern dabei verschiedene Datenschutzstrategien und Maßnahmen.
Im Projekt wurden hierzu Pseudonymisierungsstrategien für horizontale und vertikale Integration vorgeschlagen. Sie zielen darauf ab, Verknüpfungsmöglichkeiten zu minimieren und nur innerhalb einer Analyse zu ermöglichen. Je nach Integrationstyp müssen zu verschiedenen Zeitpunkten verschiedene Akteure Pseudonyme kreieren und verwalten.
In Datenräumen sollen pseudonyme Daten nur in sogenannten sicheren Verarbeitungsumgebungen analysiert werden. Das AnoMed-Team hat beschrieben, welche technischen und organisatorischen Maßnahmen zur Sicherung solcher physischen oder virtuellen Verarbeitungsumgebungen eingesetzt werden können, um eine Identifizierung zu verhindern. Ein Beispiel ist die Methode der föderierten Analyse, die es erlaubt, alle Daten an ihren Quellen zu belassen und trotzdem horizontal integrierte Analysen (z. B. Statistiken) zu erstellen.
Ob Daten erfolgreich anonymisiert worden sind oder ob eine Re-Identifizierung von Personen doch noch möglich ist, ist nicht immer bestimmbar. Zum Beispiel können neue Zusatzdaten, neue Identifizierungsmethoden oder Vervielfachung der verfügbaren Rechenleistung die Identifikation in vorher anonym geglaubten Daten ermöglichen. Um diese Situation kontrollierbar zu machen, hat das Projektteam in Analogie zur Informationssicherheit von Software das Zusammenspiel von verschiedenen Parteien in einem eigenen Ökosystem vorgeschlagen. Wesentlich dafür ist eine zentrale Anlaufstelle als Einrichtung des Datenraums mit der Aufgabe, Entwicklungen und Risiken zu beobachten. Die Einrichtung wäre mit einem CERT/CSIRT vergleichbar, das solche Aufgaben im Bereich der Informationssicherheit wahrnimmt. Eine wichtige Rolle nehmen auch Re-Identifizierungsforschende ein. Sie testen Anonymisierungsmethoden und Möglichkeiten einer Re-Identifizierung am Rande des Machbaren.
https://www.datenschutzzentrum.de/projekte/anomed/[Extern]
Kurzlink: https://uldsh.de/tb44-8-5a
| Zurück zum vorherigen Kapitel | Zum Inhaltsverzeichnis | Zum nächsten Kapitel |


