10 Aus dem IT-Labor
10.1 Datenschutzkonforme Tests durch Virtualisierung
Administratoren müssen Updates und Patches einspielen, um Betriebssysteme und Anwendungsprogramme auf einem aktuellen Sicherheits- und Funktionsstand zu halten. Die Notwendigkeit dieser Fehlerbehebungen hat in den letzten Jahren qualitativ wie quantitativ stetig zugenommen.
Ein geordnetes Sicherheitsmanagement inklusive Test und Freigabe solcher „Bugfixes“ stellt Administratoren vor Herausforderungen. Viele auf den Markt kommende Programme beinhalten derart viele Funktionen, dass es viele Hersteller, wahrscheinlich aus wirtschaftlichen Gründen, mit dem Testen nicht mehr so genau nehmen. Dies führt dazu, dass nach kurzer Zeit Korrekturen und Ergänzungen vorgenommen werden müssen. Relativ unbedenklich sind neue „Hilfe“-Dateien mit zusätzlichen Informationen für Systemverantwortliche und Anwender. Häufiger handelt es sich um Updates zu Sicherheits- oder Funktionsaspekten, die versprochene Funktionen fehlerfrei bereitstellen oder Probleme beheben sollen, die bei der Auslieferung der Software noch nicht bekannt waren. Programme werden jedoch nicht mehr isoliert eingesetzt. Schon in kleinen Netzwerken kommunizieren eine Vielzahl von Verfahren in verschiedener Weise miteinander, sodass eine kleine Veränderung in einem Programm dazu führen kann, dass andere Teile eines Verfahrens nicht mehr fehlerfrei funktionieren. Ein Administrator sieht sich in diesen Fällen gezwungen, ein Programm in einer eigentlich veralteten Version durch zeitaufwendige Backup-Prozesse zurückzuspielen.
Administratoren befinden sich dadurch häufig in einer Zwickmühle, in der sie schwerlich korrekt handeln können: Einerseits sind Sicherheitsupdates möglichst schnell zu installieren, um keine Sicherheitsvorfälle durch verzögertes Einspielen zu riskieren. Andererseits sind ausführliche Tests notwendig, um ein Zusammenspiel aller Programme und Systeme nach einem Patch oder einem Update zu überprüfen.
Beim Testen in einer realistischen Umgebung, ohne den Produktivbetrieb zu beeinträchtigen, können sogenannte Virtualisierungstechnologien helfen. Als virtuelle Systeme bezeichnet man Computer, die nicht fest an eine bestimmte physikalische Hardware gekoppelt sind. Virtualisierungsprogramme simulieren bzw. emulieren Hardware, z. B. Festplatten und Grafikkarten, und bieten somit eine virtuelle technische Umgebung, in der verschiedene Betriebssysteme installiert und eingerichtet werden können, sodass auf einer einzigen physikalischen Hardware eine Vielzahl von virtuellen Computern arbeiten. In einem solchen „virtuellen Sandkasten“ können gefahrlos neue Programmversionen getestet oder die Auswirkungen von Patches und Updates überprüft werden.
Der Vorteil ist klar: Es kann Hardware eingespart werden. Nicht jedes an einem Verfahren beteiligte System muss physikalisch kopiert als Testsystem bereitgehalten werden. In der täglichen Arbeit bieten virtuelle Maschinen noch einen weiteren Vorteil. Sie sind nicht an reale Geräte gebunden. Die Daten virtueller Maschinen lassen sich dadurch sichern, dass man simulierte Festplatten und die Konfiguration der virtuellen Umgebung als Dateien auf einer (realen) Festplatte kopiert. Diese Daten können wieder zurückgespielt werden, wenn der Originalzustand eines Betriebssystems oder eines Programms wiederhergestellt werden muss. Ein Administrator kann dadurch Software und Updates installieren und testen, ohne anschließend den Computer aufwendig neu zu installieren, falls etwas schiefläuft. Ein Zurückspielen der Dateien einer virtuellen Umgebung reicht, um die virtuelle Maschine in den Ursprungszustand zurückzusetzen.
Die Hersteller stellen ihre Virtualisierungssoftware mit vollem Funktionsumfang kostenlos zur Verfügung. Das ULD hat mehrere Virtualisierungslösungen getestet und auf virtualisierten Systemen Szenarien für Tests und Freigabe gemäß der Datenschutzverordnung durchgeführt. Unser Fazit: Testen war noch nie so einfach wie heute. Virtualisierte Testumgebungen sind als Maßnahme nach Stand der Technik anzusehen, um effektive Test- und Freigabeszenarien aufzubauen.
Was ist zu tun?
Administratoren sollten Virtualisierungssoftware einsetzen, um Updates und Veränderungen an Systemen schnell, effektiv und kostengünstig unter verschiedenen Bedingungen zu prüfen.
10.2 Terminalserver
Seit wenigen Jahren besteht der Trend, Programme und Betriebssysteme nicht mehr auf Einzel-PCs, sondern wie zu den Zeiten teurer Großrechner auf einem zentralen Server ablaufen zu lassen. Auf diesen sogenannten Terminalservern arbeiten gleichzeitig eine Vielzahl von Benutzern über preiswerte Arbeits-PCs mit diversen Programmen. Aus Datenschutzsicht ist eine solche zentral verwaltete Rechnerinfrastruktur grundsätzlich zu begrüßen.
Allerdings hat dies einen Haken: Administratoren können mit geringem Aufwand und unerkannt die Sitzungen der Benutzer lesen und steuern. Deshalb muss bei der Konfiguration der Systeme einiges beachtet werden.
Bis in die 80er-Jahre gab es meist Großrechner, an denen über einfache Textzeichenterminals gearbeitet wurde. Die Großrechner wurden Ende der 80er-Jahre zunehmend durch grafikfähige PCs ersetzt. Programme liefen nicht mehr auf einem Server, sondern lokal ab. Recht kurzfristig darauf folgte die Phase der PC‑Vernetzung. Zu Beginn des neuen Jahrtausends begann wieder ein Rezentralisierungstrend zum Terminalserver. Die steigende Komplexität der Programme und Workflows sowie die wachsenden Hardwareanforderungen weckten wieder den Wunsch, Programme und Betriebssysteme nur einmal zentral installieren, konfigurieren und pflegen zu müssen.
Moderne Terminalserverlösungen erfüllen diesen Wunsch, indem sie fast alle Arbeitsumgebungen, wie z. B. den Desktop oder Office-Anwendungen, zentral bereitstellen. Ein weiterer Vorteil ist die längere Nutzbarkeit der Hardware, denn Computer müssen nur ein Bild anzeigen können, anstatt wie bisher alle Programme lokal auszuführen. Bei einer solch zentralen Lösung ist die sogenannte Spiegelung zu beachten: Administratoren oder auch andere Benutzer mit der entsprechenden Berechtigung können sich Sitzungen von Terminalserverbenutzern anzeigen lassen und eventuell sogar aktiv steuern. Dies ist implementiert, um Anwendern möglichst effektiv direkt helfen zu können, ohne physikalisch vor Ort sein zu müssen.
Dieser Service kann aber auch zum Nachteil von Benutzern verwendet werden. Denn mithilfe dieser Funktion können Benutzeraktivitäten unkontrolliert überwacht werden – also ohne Protokollierung oder Monitoring oder ohne jedes Mal aktiv gegebene Benutzereinwilligung. Eine betroffene Person bemerkt in solchen Fällen nicht, dass ihr gesamter Bildschirminhalt z. B. beim Administrator dupliziert wird. Dies ist ein Problem bei Mitarbeitern mit Vertrauensstellung, etwa beim Personalrat, bei der Personalabteilung oder bei der Leitung. Im Produkt „Citrix Presentation Server“ sollte gleich die Installation so erfolgen, dass eine Protokollierung und eine Benachrichtigung erfolgen. In einer Dienstvereinbarung muss geregelt sein, mit welchen Konsequenzen zu rechnen ist, wenn diese Konfiguration durch die Administration unerlaubt zurückgesetzt oder umgangen wird.
Kann die Spiegelung nicht kontrolliert werden, so empfiehlt sich bei besonders schützenswerter Datenverarbeitung keine Terminalserverapplikation. Nur so lässt sich hinreichend sicher eine Kenntnisnahme Dritter ausschließen.
Was ist zu tun?
Die IT-Abteilung muss für eine saubere Protokollierung und Benachrichtigung bei Terminalserverlösungen sorgen.
10.3 Open Source in der öffentlichen Verwaltung
In München, Wien oder Mannheim, in Form einer kompletten Umstellung oder als sanfte Migration: Open Source setzt sich in Verwaltungen zusehends durch.
Das ULD bemerkt auch in Schleswig-Holstein ein gesteigertes Interesse zum Thema Datenschutz und Datensicherheit beim Einsatz von Open-Source-Programmen. Bei Schulungen der DATENSCHUTZAKADEMIE sowie in Beratungs- und Prüfungsgesprächen steht das Thema oft im Fokus. Vielen IT-Verantwortlichen erscheint schon aus wirtschaftlichen Gründen der Einsatz der meistens kostenfrei erhältlichen Programme wünschenswert.
Wie bei kommerziellen Programmen müssen auch beim Einsatz von Open-Source-Software stets die folgenden Fragen geklärt werden:
- Erfüllt die Software die in sie gestellten Anforderungen?
- Ist die Software sauber programmiert?
- Handelt es sich um Software aus vertrauenswürdigen Quellen?
- Ist die Pflege und Weiterentwicklung der Software mittelfristig sichergestellt?
- Ist innerhalb der Organisation ausreichendes Wissen zum Betrieb der Software vorhanden?
- Gibt es Dienstleister, die bei Planung, Einführung und Betrieb der Software unterstützen können?
Kritisch betrachtet ist festzustellen, dass diese Anforderungen auch von herkömmlichen kommerziellen Anbietern oft nicht zureichend erfüllt werden. Das ULD setzt seit Jahren selbst quelloffene Software ein. Unsere praktischen Erfahrungen beim Einsatz insbesondere in sicherheitskritischen Bereichen erlauben insgesamt ein positives Zwischenfazit. Der Einsatz bereits etablierter und renommierter Open-Source-Software bietet einen deutlichen Sicherheitsgewinn gegenüber kommerzieller Software mit unklarer Dokumentationslage oder Zukunftsperspektive.
Was ist zu tun?
IT-Planer müssen jede Art von Software vor dem Einsatz ausreichend prüfen und dabei die Vor- und Nachteile der unterschiedlichen Lösungen gegeneinander abwägen. Grundsätzliche Vorbehalte gegenüber Open-Source-Software sind nicht gerechtfertigt.
10.4 Online-Banking – auf der Suche nach der sicheren Seite
Bankgeschäfte online abzuwickeln, ist ein verlockender Gedanke. Obwohl entsprechende Verfahren schon seit Jahren von den Banken angeboten werden, zeigen sich viele Bürgerinnen und Bürger nach wie vor besorgt über die Sicherheit solcher Online-Transaktionen.
Das meistverwendete Verfahren zur Authentifizierung beim Online-Banking ist nach wie vor das PIN/TAN-Verfahren in seinen unterschiedlichen Varianten. Die unter Sicherheitsaspekten vorzuziehende Alternative HBCI fristet noch immer ein Schattendasein (27. TB, Tz. 10.3), zu aufwendig erscheint Nutzern und Banken die Verwendung einer Chipkarte samt extra Lesegerät. An der Installation der notwendigen Treiber und Programme scheitern technisch weniger versierte Anwender. Die Vorteile des PIN/TAN-Verfahrens hingegen liegen oberflächlich betrachtet auf der Hand: Es wird weder Software noch Hardware benötigt; der Nutzer kann seinen gewohnten Browser unverändert verwenden; man ist vom Rechner unabhängig – PIN/TAN funktioniert auf jedem internetfähigen PC; ein lästiger Kartenleser ist nicht notwendig.
Doch PIN/TAN-Verfahren haben einen Nachteil: Wer Kenntnis von PIN und TAN erlangt, kann die zugehörigen Transaktionen ändern. Das bereitet den Boden für sogenannte Phishing-Angriffe (27. TB, Tz. 10.3) und spezialisierte Würmer. Das HBCI-Verfahren mit Chipkarte hingegen setzt auf einen externen Kartenleser, dessen eigentliche Funktion vom PC unabhängig ist. So werden die kryptografischen Berechnungen direkt im Kartenleser ausgeführt, und der Nutzer authentifiziert sich durch seine Chipkarte und eine PIN, die direkt am Kartenleser eingetippt wird. Dabei ist es unerheblich, ob ein Schädling den PC befallen hat: Der Kartenleser kommuniziert über Zertifikate direkt mit der Bank, Fälschungen sind hier nach dem Stand der Technik nicht möglich.
Statt HBCI mit Chipkarte großflächig den eigenen Kunden anzubieten, versuchen die Banken mit allerlei Erweiterungsvarianten das PIN/TAN-Verfahren am Leben zu halten. Mit eTAN, iTAN und mTAN will man den Bedrohungen durch Online-Betrüger begegnen. Doch die neuen Verfahren, die entweder auf spezielle Geräte (eTAN), durchnummerierte TAN-Listen (iTAN) oder das Handy des Nutzers (mTAN) setzen, sind nur eine Behandlung von Symptomen. Phishing-Angriffe, bei denen die PIN und eine gültige TAN ergaunert werden sollen, können zwar unterbunden werden. Angriffe wie das Abhören der Verbindung und Verändern von Inhalten („Man in the middle“-Angriff) sind aber auch mit erweiterten TAN-Verfahren möglich. Wie fahrlässig manche Banken beim Online-Banking vorgehen, zeigte im Oktober 2006 die Citibank. Die dort ausgegebenen TAN-Listen enthielten keine reinen Zufallszahlen, sondern wiesen eine Systematik auf, die die Wahrscheinlichkeit, einzelne TANs zu erraten, deutlich erhöhte.
Was ist zu tun?
Das HBCI-Verfahren mit Chipkarte ist mit allen Mitteln zu unterstützen! Kunden sollten sich bei ihren Banken nach HBCI erkundigen und sich nicht scheuen, dieses Verfahren trotz geringfügiger Mehrkosten und größerem Installationsaufwand einzusetzen.
10.5 Identitätsdiebe im Internet ?
Zunehmend wenden sich besorgte Bürger an das ULD, die unter ihrem Namen Beiträge in Internetforen finden oder Opfer gefälschter E-Mails geworden sind. Oft ist die Unbedarftheit der Nutzer die Ursache für den Missbrauch ihrer Identität durch andere. Manchmal sind es technische Besonderheiten, die Bürger verunsichern.
- Fall 1: „Google durchsucht/scannt meine Festplatte!“
Jemand beklagte sich, dass bei einer Google-Suchanfrage nicht nur Webseiten angezeigt wurden, die das Suchwort enthielten, sondern auch seine privaten Dateien und E-Mails, auf die die Suche zutraf. In der Tat kann Google lokale Dateien des Nutzers analysieren, allerdings nur, wenn die Software „Google Desktop“ installiert ist. Und auch dann wird zuerst die Suche im Internet durchgeführt und das dort erhaltene Suchergebnis lokal mit den Treffern auf dem eigenen PC angereichert. Für den Nutzer erscheint dies jedoch als ein einziges Suchergebnis (Tz. 10.7).
- Fall 2: „Bei Google sieht man alle Seiten, die ich besucht habe!“
Eine besorgte Dame hatte bei einem Bekannten beobachtet, welche Treffer Google bei der Suche nach ihrer Mailadresse anzeigte. Sie hatte daraufhin den Verdacht, ihr Surfverhalten würde aufgezeichnet. Konkret war dem allerdings nicht so. Vielmehr war die Petentin sehr aktiv in Internetforen, wo sie ihre Beiträge stets mit dem gleichen Nutzernamen und derselben E-Mail-Adresse unterschrieb. Internetsuchmaschinen wie Google listen bei einer Suche nach der betreffenden Mailadresse all diese Seiten auf.
- Fall 3: „Meine Bekannten erhalten Spam-Mails unter meinem Namen!“
Wer E-Mails von Bekannten erhält, vertraut im Allgemeinen darauf, dass diese seriös sind. Umso irritierter sind viele Nutzer, wenn sie von den vermeintlichen Adressen bekannter Personen Spam-Mails oder gar Viren erhalten. Dabei ist zu beachten, dass die Angabe des Absenders bei einer E-Mail sehr leicht gefälscht werden kann – vergleichbar mit einem Briefumschlag, auf dessen Rückseite man einen falschen Namen als Absender einträgt. Spam-Versender geben oft falsche und vermeintlich vertrauenswürdige Absenderadressen an, um Nutzer zum Lesen ihrer Nachrichten zu bewegen. Adressenlisten zum Spam-Versand werden oft durch Wurmprogramme generiert, die befallene Rechner nach Mailadressen durchsuchen, z. B. durch Auswertung des E-Mail-Programms. So geraten dann Adressen von persönlich miteinander bekannten Menschen auf die Listen von Spam-Versendern. Diese erzeugen ihre Mails dann, indem sie eine Adresse der Liste als Empfänger, die andere als Absender eintragen.
Diese Fälle zeigen eine spürbare Besorgnis bei Bürgerinnen und Bürgern über den Missbrauch ihrer Identität im Internet. Da viele technische Zusammenhänge für Normalanwender nur schwer zu durchschauen sind, stellen sich manche Bedenken bei Anfragen als glücklicherweise unbegründet heraus. Die genannten Beispiele machen jedoch deutlich, wie arg- und sorglos manche Nutzer mit Informationen über ihre Person im Netz umgehen. Dass Beiträge unter demselben Nutzernamen von einer Suchmaschine gefunden werden, sollte keine Überraschung sein; schließlich ist es die Aufgabe einer Suchmaschine, Webseiten anhand von Stichworten zu finden.
Nutzer sollten darauf achten, im Internet unter Pseudonymen zu agieren, wenn eine Verkettung von personenbezogenen Informationen mit einfachen Mitteln wie Google verhindert werden soll. Anonymisierungsdienste wie AN.ON können dabei nur unterstützen, denn die Anonymisierung der IP-Adresse bringt nichts, wenn der Nutzer seine echte Mailadresse auf der Zielseite angibt. Einwegmailadressen wie www.temporaryinbox.com helfen hier einen Schritt weiter.
E-Mails sind generell mit Skepsis zu betrachten. Bekannte Absendernamen garantieren keine Vertrauenswürdigkeit. Einzig elektronische Unterschriften, sogenannte digitale Signaturen, können die Authentizität belegen, z. B. mittels GnuPG oder X.509-Zertifikat. Obwohl die meisten Nutzer regelmäßig mit gefälschten Absenderadressen konfrontiert werden, hat sich die Nutzung von digitalen Signaturen noch nicht durchgesetzt.
An den Beispielen und Lösungsmöglichkeiten wird deutlich, dass es dem Nutzer überlassen bleibt, das Maß seiner Anonymität im Netz zu bestimmen. Technische Hilfsmittel, die ein wirkungsvolles Management verschiedener Online-Identitäten ermöglichen oder unterstützen, befinden sich noch im Entwicklungsstadium, wie z. B. MozPET. Das ULD ist im Projekt PRIME aktiv an der Entwicklung eines Identitätsmanagers beteiligt (Tz. 8.4). Bis zur Marktreife dieser Werkzeuge bleibt es Aufgabe des Nutzers, stets aufs Neue zu entscheiden, welche Informationen er über sich preisgibt und welches Risiko er damit einzugehen bereit ist.
![]() mozpets.sourceforge.net/
mozpets.sourceforge.net/
10.6 Google
Aufgrund des enormen Wachstums des World Wide Web ist es den Nutzerinnen und Nutzern nicht mehr möglich, den Überblick über die Vielfalt von Angeboten zu bewahren. Als große Hilfe erweisen sich die Internetsuchmaschinen, von denen sich Google als meistfrequentierte Suchmaschine zum Klassenprimus mauserte. Diese Vormachtstellung zementiert Google durch viele zusätzliche Dienste, die bei Datenschützern auf Argwohn stoßen.
Die Konkurrenz ist groß im Suchmaschinengeschäft. Schon lange reicht es nicht mehr aus, die Nutzer über einen reinen Suchdienst an seine Seite zu binden. Über das Angebot zusätzlicher Dienste soll dem Nutzer ein Mehrwert bei Inanspruchnahme geboten werden, damit er der Suchseite treu bleibt. Google hat im Laufe der letzten Jahre eine Reihe von Zusatzdiensten ins Netz gestellt, die nicht nur den Nutzern, sondern auch Google einen Mehrwert in Form von Personendaten bieten. Zu diesen Diensten zählen GMail, Google Desktop, Google Maps, Google Analytics und Google Toolbar.
Für sich genommen weist jeder dieser Zusatzdienste schon ein recht hohes Datenschutzdefizit auf, zumal die erfassten personenbezogenen Daten in den Vereinigten Staaten von Amerika (USA) gespeichert werden. Ernsthafte Befürchtungen begründet allerdings die Vorstellung, dass sämtliche erhobene Daten der vielen Dienste von Google zusammengeführt werden. Rechtlich verhindern lässt sich das nicht, da die Verarbeitung in den USA erfolgt, wo keine Datenschutzstandards wie in Europa herrschen.
Dem Nutzer selbst ist dieser Umstand nicht bewusst. Er weiß in der Regel nicht, welche Daten von ihm erfasst werden und wo diese dann lagern. Ebenso fehlt das Wissen über die mögliche Zusammenführung von Daten, deren Auswertung und der dadurch qualitätssteigernden Aussagekraft. Hier hilft nur eine klare und ausführliche Unterrichtung der Nutzer über die mögliche Bildung von Metaprofilen und deren Informationsgehalt.
Obendrein genießt Google bei den meisten Nutzern immer noch den Nimbus eines Underdogs, der an der Seite des kleinen Mannes steht. Durch das Anbieten von hochwertigen Gratisprogrammen wie Picasa oder Google Earth wird diese Wahrnehmung gefestigt. Dieser Status ist längst überholt, wie aktuellen Fakten zu dem Unternehmen zeigen (Stand November 2006). Der Internetkonzern beschäftigt weltweit mehr als 5000 Menschen und besitzt zurzeit einen Börsenwert von 120 Milliarden Euro. Alteingesessene Industriekonzerne wie BMW oder DaimlerChrysler besitzen nur ein Drittel des Börsenwertes von Google. Jedem sollte bewusst sein, dass der Internetriese im Kampf gegen seine Konkurrenten keinen Anlass hat, etwas zu verschenken, schon gar nicht den enormen Wert seiner vorliegenden Nutzerdaten.
10.7 Google Desktop
Tausende Dateien schlummern auf den Festplatten unserer PCs – Textdokumente, Bilder und Musik. Der Überblick fällt vielen Nutzern schwer. Der Wunsch nach Helfern im Chaos ist daher groß, und wer sollte solch ein Chaos besser zu ordnen wissen als der Suchmaschinenprimus aus dem Internet: Google?
Viele Nutzer haben ein ungutes Gefühl, wenn Google in ihren privaten Dokumenten stöbert – nicht zu Unrecht: Die Suchmaschine verwaltet die gewonnenen Daten nicht nur auf dem Rechner des Nutzers. Die Theorie ist einfach: Ein Programm auf dem eigenen Rechner durchsucht die eigenen Dateien und kann dem Nutzer später sagen, was wo gespeichert ist. Der Brief ans Finanzamt? Hier! Die Bilder von Omas Hochzeit? Da! Aber der Teufel steckt im Detail. Google Desktop erzeugt bei der Installation für den aktuellen Computer eine weltweit einmalige Identifikationsnummer, eine sogenannte GUID (Globally Unique Identifier). Diese Nummer wird nach erfolgreicher Installation an Google gesendet. Des Weiteren wird diese Nummer jedes Mal an Google übermittelt, wenn das Programm nach Updates sucht – also sobald der Rechner eingeschaltet wird und ans Datennetz geht.
Google erfährt so umgehend, welches seiner Schäfchen da ins Internet zurückkehrt. Die GUID bleibt gleich. So ist es völlig egal, ob die Nutzer Anonymitätsdienste verwenden oder fleißig ihre Cookies löschen. Google weiß, sobald der Rechner eine gültige IP-Adresse zugewiesen bekommen hat, welcher seiner Nutzer gerade online ist. Da bei der Übertragung der GUID die vom Provider zugewiesene IP-Adresse als Absender mitgeliefert wird, ist Google stets im Bilde, welcher PC aktuell mit welcher IP-Adresse im Internet unterwegs ist.
Ein Nutzer, der seine Cookies gelöscht hat, ist beim erneuten Besuch einer Webseite ein „neuer“ unbekannter Nutzer. Die Seite kann nicht erkennen, ob dieser Rechner schon einmal mit ihr verbunden war oder nicht. Dank Googles GUID weiß zumindest der Suchmaschinenriese, welche PCs da durchs Internet geistern. Von der Erzeugung der GUID wird der Nutzer indes nicht sonderlich auffällig informiert. Er muss sich die Information aus der allgemeinen Datenschutzerklärung heraussuchen, die zudem auch nicht selbstständig, sondern erst nach entsprechendem Klick geöffnet wird.
Doch die GUID ist nicht alles, was Google in seiner Desktop-Suche versteckt hat. Seit Version 3 ermöglicht Google Desktop eine Übertragung des angelegten Index auf die Server von Google. Mit dieser Funktion ist es einem Nutzer z. B. möglich, von seinem Büro-PC mithilfe von Google Desktop auch in den Dokumenten des Heim-PCs zu suchen, da der erforderliche Index auf den Google-Servern im Internet liegt. Damit hat Google – zumindest aus technischer Sicht – Zugriff auf alle Daten, die auf dem Nutzer-PC gespeichert sind, denn schließlich enthält der Index nicht nur Dateinamen, sondern auch den Inhalt der Dokumente, um darin Suchoperationen ausführen zu können. Seitens der US-Behörden gab es bereits Begehrlichkeiten in Bezug auf Internetsuchanfragen bei Google. Es ist eine Frage der Zeit, bis die Google-Desktop-Dateien insofern in den Fokus geraten. Da die fraglichen Server ausschließlich in den USA stehen, ist eine Durchsetzung deutscher Datenschutzansprüche schwieriger als hierzulande – bis praktisch unmöglich.
Ein kleiner Trost besteht immerhin im Beitritt und Bekenntnis Googles zum „Safe-Harbor-Abkommen“. Die Datensammlung an sich wird dadurch allerdings nicht weniger problematisch.
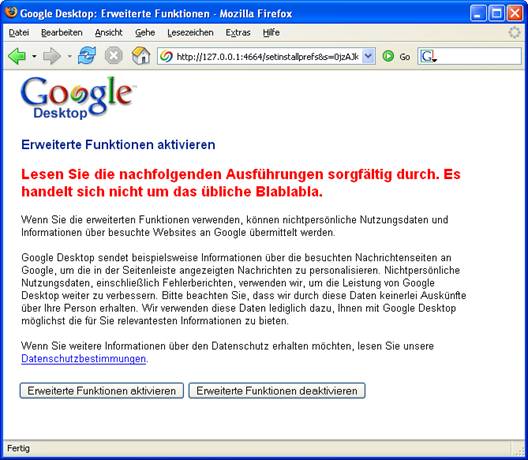
Immerhin kann die Funktion zum Übertragen des Suchindex abgeschaltet werden. Das sollte man auch unbedingt tun, denn unter der Aktivierung der „Erweiterten Funktionen“ von Google Desktop versteht der Hersteller nicht nur die Kopie des Index auf die eigenen Server. Sollte der Nutzer diese Funktion aktivieren, „verschickt Google Desktop gegebenenfalls Informationen über die […] besuchten Webseiten“ und sammelt „eine begrenzte Zahl nicht personenbezogener Daten“ des Computers: „Hierzu gehören […] die Anzahl der […] durchgeführten Suchanfragen sowie die Zeit, die Sie bis zum Anschauen der Ergebnisse brauchen, und Anwendungsberichte, die wir benutzen, um das Programm zu verbessern.“
Google protokolliert also in aller Deutlichkeit das Online-Verhalten seiner Nutzer. Eine technische Notwendigkeit zur Erfassung z. B. der Betrachtungsdauer von Webseiten lässt sich kaum konstruieren. Der brave Hinweis, die Daten enthielten keinerlei Auskünfte zur Person des Nutzers, ist dabei einfach falsch: Die übertragenen Suchindizes sind schon durch ihren Inhalt eindeutig personenbezogen, und aus Nutzerdaten und GUID lassen sich exzellente Profile bilden. Hier versteckt sich Google einmal mehr hinter der Behauptung, ein einzelnes Datum habe keinen Personenbezug. Dass dieser Bezug auf den Rechnern von Google durch Kombination mit anderen, für sich genommen ebenfalls unpersönlichen Informationen leicht hergestellt werden kann, verschweigt der Suchmaschinenriese geflissentlich.
Ein weiteres Problem tritt für Nutzer auf, die die Funktion der Desktop-Suche nicht komplett durchschauen. Ist das Programm auf dem eigenen PC installiert, blendet Google Desktop bei jeder Internetsuche die Fundstellen in lokalen Dateien im Browser ein. Wer nach „Quarkstrudel“ sucht, erhält in seinem Browser zuerst alle Dokumente des eigenen PCs, die den Begriff enthalten, und danach die betreffenden Internetseiten. Dass dabei die eine Hälfte der Ergebnisseite vom lokalen Programm, die andere Hälfte vom Google-Server im Internet erstellt wird, ist für Normalnutzer nicht ersichtlich. Verunsicherte Bürger, die sich beim ULD meldeten, weil „Google auf ihre Festplatte schauen kann“, waren nicht selten. Tatsächlich kann Google zuerst einmal nicht auf die lokalen Daten zugreifen, sondern blendet diese Ergebnisse mithilfe von Google Desktop lokal ein. Erst wenn die oben beschriebenen „Erweiterten Funktionen“ aktiviert werden, landen die Daten des eigenen PCs wirklich bei Google in den USA.
Wer auf Nummer sicher gehen will, deaktiviert diese Funktion daher oder verwendet eine andere Software, die das Gleiche leistet, aber kein so ausgeprägtes „Sendungsbewusstsein“ an den Tag legt.
10.8 Google Toolbar
Spezielle Symbolleisten für Browser – sogenannte Toolbars – bieten die Möglichkeit, Spezialfunktionen zu nutzen, die der Browser von Haus aus nicht bietet. Google hat eine solche Toolbar im Angebot. Und wieder bedeutet die Nutzung für den Anwender ein weiteres Stück Verlust der Privatsphäre.
Mit der Google Toolbar lassen sich nützliche Aufgaben erledigen. Das Programm dient als Rechtschreibkontrolle im Browser; es vermag Phishing-verdächtige Webseiten zu markieren und zeigt den „PageRank“ an, die Wichtigkeit einer besuchten Internetseite nach Google-Maßstäben.
Dass die Toolbar nicht irgendein kleines Werkzeug ist, ahnt man schon bei der Installation. Hier weist Google darauf hin, dass zur Ausführung bestimmter Funktionen „Informationen über besuchte Websites an Google übermittelt werden“. Mit anderen Worten: Wer die Google Toolbar verwendet, surft fortan mit Beifahrer. Um z. B. den PageRank einer Webseite beurteilen zu können, muss Google wissen, um welche Seite es sich handelt, ebenso, um den Nutzer vor Phishing-verdächtigen Seiten zu warnen. Auf diese Weise entsteht bei Google ein komplettes Bild der Surfgewohnheiten seiner Toolbar-Nutzer. Wer wann wohin surft, welche Links er anklickt, wie lange er verweilt, welche Suchbegriffe er verwendet, all das wird protokolliert und übermittelt. Wenn man mithilfe der Toolbar seine Lesezeichen zentral bei Google ablegt, erhält Google auch einen Einblick, für was sich die Nutzer dauerhaft interessieren.
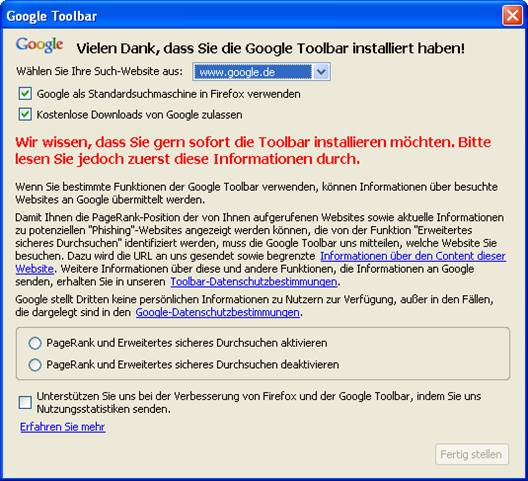
Schaltet man die problematischen Funktionen ab, bleiben Extras wie RSS-Abonnement und Rechtschreibprüfung – Funktionen, die moderne Browser wie Firefox schon von Haus aus mitbringen. Ein wahrer Mehrwert der Google Toolbar für den Nutzer bleibt somit fraglich.
10.9 Google-Szenario
Das Angebot von Zusatzdiensten ist bei Google sehr umfangreich. Um einen Einblick über die mögliche Zusammenführung von Daten aus verschiedenen Google-Diensten zu erhalten, wird im Nachfolgenden ein Szenario entworfen, wie ein beispielhafter Handlungsablauf eines typischen Internetnutzers aussehen kann. Hierbei wird verdeutlicht, welche Daten an Google fließen und welchen Informationsgehalt sie besitzen.
Der Internetnutzer Herr Mustermann schaltet seinen Rechner an. In dem Moment, in dem eine Verbindung zum Internet aufgebaut worden ist, verbindet sich das installierte Programm Google Desktop mit dem Google-Server und übermittelt dorthin seine eindeutige Kennung – die sogenannte GUID – inklusive der aktuellen IP-Adresse. Herr Mustermann bekommt davon nichts mit; er ist selbst noch nicht im Internet unterwegs. Da er seine Desktop-Suche im „erweiterten Modus“ betreibt, überträgt das Programm seinen Suchindex – ein Verzeichnis aller Begriffe, die in sämtlichen Dokumenten auf seiner Festplatte vorkommen – an Google. Aus diesen Begriffen lassen sich ohne Weiteres Rückschlüsse auf berufliche und private Interessen von Herrn Mustermann ziehen. Herr Mustermann ist immer noch nicht aktiv im Internet tätig gewesen. Eventuell schaltet er seinen Computer wieder aus, hat aber ohne sein Wissen seine bei Google gespeicherten Daten aktualisiert.
Nun ruft Herr Mustermann seinen Browser auf. Dessen Startseite ist die Google-Homepage. Der Browser lädt die Webseite und speichert einen Cookie, den er von Google erhält. Der Cookie macht den Browser für den Google-Server fortan wiedererkennbar. Alle Google-Suchaktivitäten von Herrn Mustermann können ab jetzt über die IP-Adresse den bereits erfassten Daten zugeordnet werden. Aber zunächst ruft Herr Mustermann sein Google-Mail-Konto ab, um zu erfahren, ob neue E-Mails für ihn eingetroffen sind. Seine GMail-Adresse setzt sich wie bei vielen Nutzern aus Vorname, Nachname und der GMail-Endung zusammen. Dadurch bekommen alle bereits gesammelten Daten einen Namen: Die GUID von Google Desktop und der Cookie im Browser gehören zu Herrn Mustermann und dessen Adresse max.mustermann@gmail.com. Spätestens an dieser Stelle erhalten also Daten bei Google einen Personenbezug, die diesen eigentlich gar nicht aufweisen sollten.
Das E-Mail-Postfach von Herrn Mustermann ist von Google im Vorfeld bereits analysiert worden, sodass er bei der Anzeige der Mails auch Werbebanner eingeblendet bekommt, die mit dem Inhalt der Nachrichten korrespondieren.
Herr Mustermann surft und gelangt zu einer Seite, auf der kleine Werbeeinblendungen von „AdSense“ angezeigt werden. Dieser Dienst von Google blendet auf diversen Seiten Werbetexte ein, die sich der Browser von Herrn Mustermann vom Google-Server abholt. Google erfährt zum einen dessen Cookie, zum anderen die angesurfte Webseite. Die besuchte Seite kann Herrn Mustermann direkt zugeordnet werden. Da Herr Mustermann noch schnell wissen möchte, was es Neues in der Welt gibt, ruft er seine persönliche Google-Nachrichtenseite auf. Hier hat er voreingestellt, dass ihn nur die Themen Politik International und Sport interessieren. Die Themen Gesundheit und Unterhaltung hat er deaktiviert. Google erfährt an dieser Stelle zunächst, dass Herr Mustermann zurückkehrt, denn auch hier wird sein Google-Cookie ausgelesen und weist ihn gegenüber der Webseite aus. Da Google den Cookie intern bereits mit Herrn Mustermanns Namen verknüpft hat, kann auch sein Verhalten auf der Nachrichtenseite exakt zugeordnet werden. Google erfährt, welche Nachrichten ihn generell interessieren und welche speziellen Artikel aus dem Angebot er anklickt und liest.
Schließlich kommt Herr Mustermann auf die Idee, maps.google.de aufzurufen. Kollegen haben ihm erzählt, dass auf dieser Webseite sehr schöne und detailgetreue Karten und Luftaufnahmen von fast der gesamten Erdoberfläche zu sehen sind. Neugierig auf diesen Service agiert Herr Mustermann wie die meisten neuen Nutzer von Google Maps: Er gibt seine eigene Adresse ein, um zu sehen, wie sein Wohnort von oben abgelichtet ist. So kann Google seinem Namen eine Adresse und deren Geokoordinate zuordnen, sofern diese nicht als Mailabspann sowieso schon bei GMail vorliegt.
Fassen wir zusammen: Bei einem beispielhaften Gebrauch von Google-Diensten, wie er oben beschrieben ist, erhält Google folgende Daten:
- Den vollständigen Namen plus Adresse und Telefonnummer (GMail, Google Desktop, Google Maps),
- einen Index von Begriffen aus Terminkalender, Adressbüchern, Mails, Dokumenten, Tabellen usw. (Google Desktop),
- Stichworte zu Vorlieben, Interessen, Hobbys auch in Bezug auf Politik, Religion und Sex (Google, Google News, Google Toolbar …).
Diese Darstellung ist nicht vollständig; beim Nutzen von weiteren Google-Diensten können noch mehr Daten erhoben werden. Vorausgesetzt wurde eine sorglose Nutzung des Internets durch Herrn Mustermann, die aber durch die meisten Nutzer praktiziert wird.
Angegeben sind die Daten, die von den Google-Diensten erhoben werden. Ein Beweis für deren Zusammenführung und Auswertung jedoch existiert bisher nicht. Es liegt allerdings aus marketingstrategischer Sicht nahe, genau diese Profilbildung durchzuführen, zumal wenn sich ein Unternehmen hieran nicht durch strenge Datenschutzregelungen gehindert sieht. Die entstehenden Nutzerprofile sind aufgrund ihres Umfangs und ihrer Qualität vor allem auf dem Werbemarkt Gold wert. Der Nutzen, den diese Profile zudem für Regierungsbehörden in den USA besitzen können, ist immens. Das US-Justizministerium hat schon bei Google angeklopft und nach Logdateien gefragt. Auch für eine enge Zusammenarbeit mit der CIA gibt es Hinweise.
| Zurück zum vorherigen Kapitel | Zum Inhaltsverzeichnis | Zum nächsten Kapitel |


